Motivation
Existing Method
- The inefficiency of existing exploration-based approaches stems from low-quality search spaces, which are large but nearly all the program candidates are invalid to meet the architectural constraints of DLAs.
- it is quite difficult to accurately constrain the search space because of the diverse and complicated architectural constraints of DLAs. The challenges of defining and exploring the search spaces for DLAs Observation #1: There exists a large number of diverse and complicated architectural constraints in DLAs Observation #2: High-quality search spaces are hard to be accurately described with a small number of intuitive hand-written constraints Observation #3: Existing search algorithms fail to explore such high-quality while irregualr search space efficiently
Overview
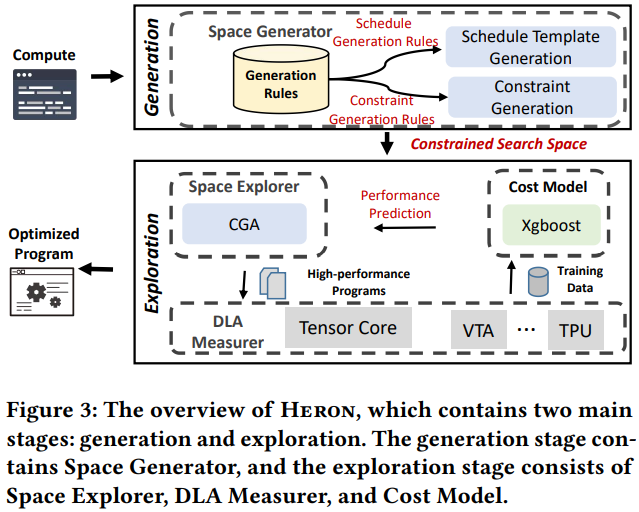
Constrained Space Generation


- Tensorize: 检查当前节点是否可以使用硬件张量使用,将计算替换为硬件内置的张量计算指令
- Add Multi-Level SPM: 为数据移动生成多个节点,在不同级别的片上存储之间移动数据
- Add Multi-Scope SPM: 为不同类型数据的移动生成节点 S2关注同一类型数据在不同层级间的移动,S3关注不同类型数据使用独立的存储路径

- AddLoopSplit: 检查循环是否被分割,确保分割后的子循环长度乘积等于原循环长度
- AddLoopFuse: 检查循环是否被融合,确保融合后循环长度等于原循环长度
- AddCandidates: 检查是否有候选值限制,限制变量只能取特定值
- AddStageFuse: 检查计算阶段是否被融合,处理融合后的阶段计算位置和循环长度关系
- AddMemLimit: 检查是否使用片上存储
- AddDLASpecific: 为特定DLA生成专门的约束

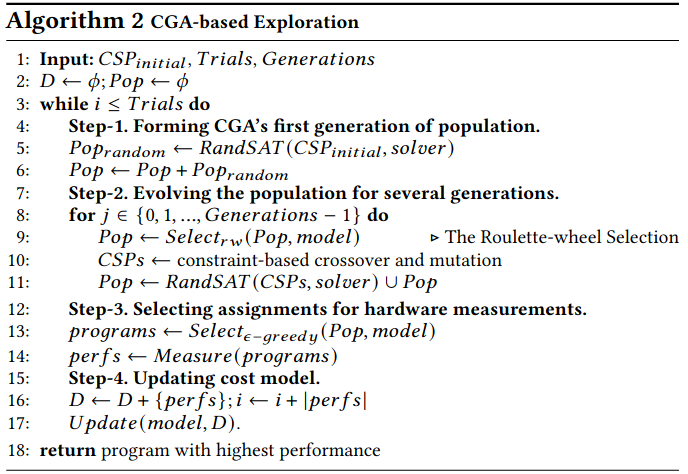
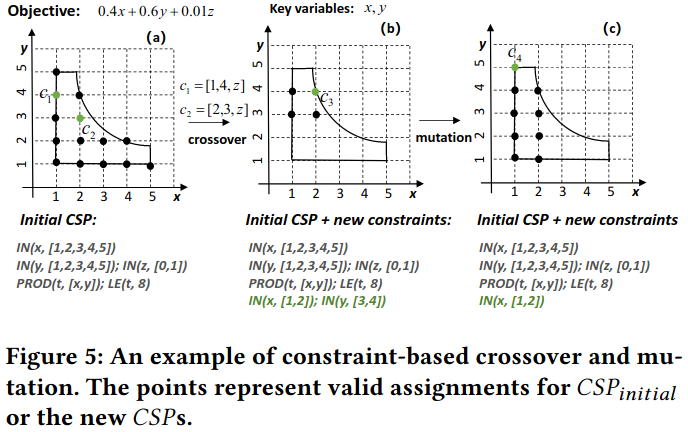
Constrained Space Exploration

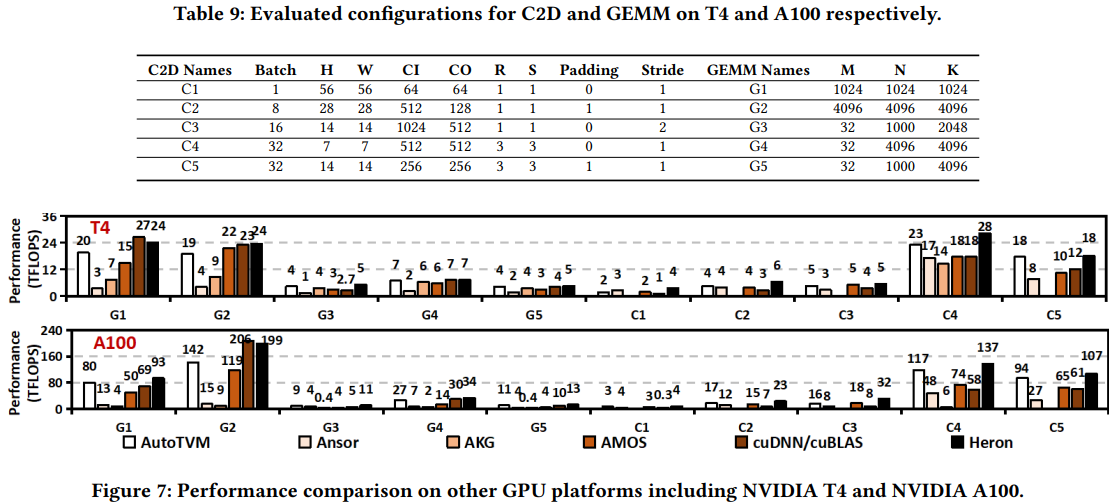
Evaluation


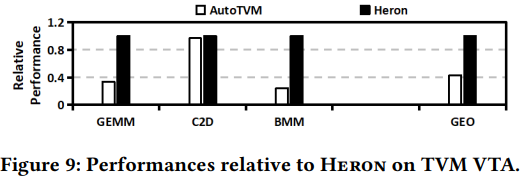
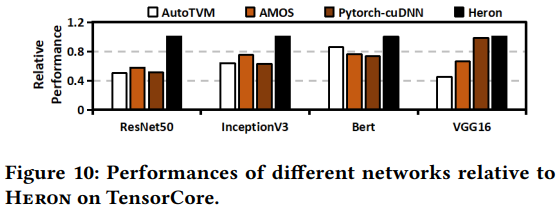
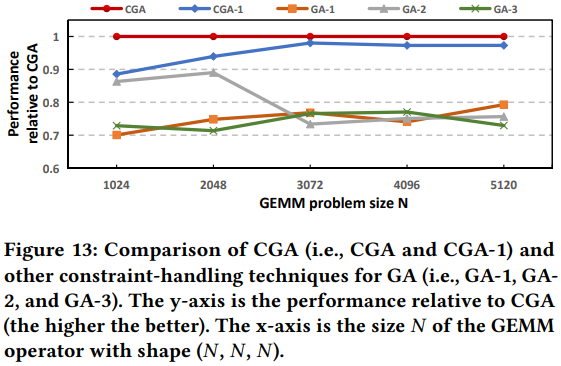
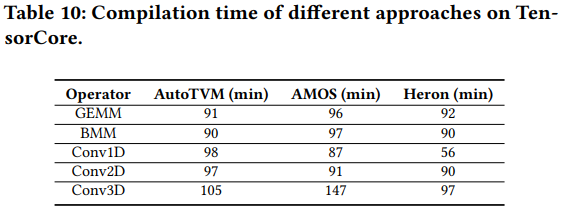
Reference
Heron: Automatically Constrained High-Performance Library Generation for Deep Learning Accelerators
FEATURED TAGS
Genetic Algorithm
Multi-objective Optimization
Instruction-Level Parallelism(ILP)
Compiler
Deep Learning Accelerators
Tensor Compiler
Compiler Optimization
Code Generation
Heterogeneous Systems
Operator Fusion
Deep Neural Network
Recursive Tensor Execution
Deep Learning
Classical Machine Learning
Compiler Optimizations
Bayesian Optimization
Autotuning
Spatial Accelerators
Tensor Computations
Code Reproduction
Neural Processing Units
Polyhedral Model
Auto-tuning
Machine Learning Compiler
Neural Network
Program Transformations
Tensor Programs
Deep learning
Tensor Program Optimizer
Search Algorithm
Compiler Infrastructure
Scalalbe and Modular Compiler Systems
Tensor Computation
GPU Task Scheduling
GPU Streams
Tensor Expression Language
Automated Program optimization Framework
AI compiler
memory hierarchy
data locality
tiling fusion
polyhedral model
scheduling
domain-specific architectures
memory intensive
TVM
Sparse Tensor Algebra
Sparse Iteration Spaces
Optimizing Transformations
Tensor Operations
Machine Learning
Model Scoring
AI Compiler
Memory-Intensive Computation
Fusion
Neural Networks
Dataflow
Domain specific Language
Programmable Domain-specific Acclerators
Mapping Space Search
Gradient-based Search
Deep Learning Systems
Systems for Machine Learning
Programming Models
Compilation
Design Space Exploration
Tile Size Optimization
Performance Modeling
High-Performance Tensor Program
Tensor Language Model
Tensor Expression
GPU
Loop Transformations
Vectorization and Parallelization
Hierarchical Classifier
TVM API
Optimizing Compilers
Halide
Pytorch
Optimizing Tensor Programs
Gradient Descent
debug
Automatic Tensor Program Tuning
Operators Fusion
Tensor Program
Cost Model
Weekly Schedule
Spatio-temporal Schedule
tensor compilers
auto-tuning
tensor program optimization
compute schedules
Tensor Compilers
Data Processing Pipeline
Mobile Devices
Layout Transformations
Transformer
Design space exploration
GPU kernel optimization
Compilers
Group Tuning Technique
Tensor Processing Unit
Hardware-software Codeisgn
Data Analysis
Adaptive Systems
Program Auto-tuning
python api
Code Optimization
Distributed Systems
High Performance Computing
code generation
compiler optimization
tensor computation
Instructions Integration
Code rewriting
Tensor Computing
DSL
CodeReproduction
Deep Learning Compiler
Loop Program Analysis
Nested Data Parallelism
Loop Fusion
C++
Machine Learning System
Decision Forest
Optimizfing Compiler
Decision Tree Ensemble
Decision Tree Inference
Parallelization
Optimizing Compiler
decision trees
random forest
machine learning
parallel processing
multithreading
Tree Structure
Performance Model
Code generation
Compiler optimization
Tensor computation
accelerator
neural networks
optimizing compilers
autotuning
performance models
deep neural networks
compilers
auto-scheduling
tensor programs
Tile size optimization
Performance modeling
Program Functionalization
affine transformations
loop optimization
Performance Optimization
Subgraph Similarity
deep learning compiler
Intra- and Inter-Operator Parallelisms
ILP
tile-size
operator fusion
cost model
graph partition
zero-shot tuning
tensor program
kernel orchestration
machine learning compiler
Loop tiling
Locality
Polyhedral compilation
Optimizing Transformation
Sparse Tensors
Asymptotic Analysis
Automatic Scheduling
Data Movement
Optimization
Operation Fusion
Compute-Intensive
Automatic Exploration
data reuse
deep reuse
Tensorize
docker
graph substitution
compiler
Just-in-time compiler
graph
Tensor program
construction tensor compilation
graph traversal
Markov analysis
Deep Learning Compilation
Tensor Program Auto-Tuning
Decision Tree
Search-based code generation
Domain specific lanuages
Parallel architectures
Dynamic neural network
mobile device
spatial accelerate
software mapping
reinforcement learning
Computation Graph
Graph Scheduling and Transformation
Graph-level Optimization
Operator-level Optimization
Partitioning Algorithms
IR Design
Parallel programming languages
Software performance
Digitial signal processing
Retargetable compilers
Equational logic and rewriting
Tensor-level Memory Management
Code Generation and Optimizations
Scheduling
Sparse Tensor
Auto-Scheduling
Tensor
Coarse-Grained Reconfigurable Architecture
Graph Neural Network
Reinforcement Learning
Auto-Tuning
Domain-Specific Accelerator
Deep learning compiler
Long context
Memory optimization
code analysis
transformer
architecture-mapping
DRAM-PIM
LLM