Motivation
Existing Method’s Problem:
(1) Continuous advances in computation throughtput leads to an increasing portion of non-computation overhead
(2) Ever-present, non-negligible CPU workloads exacerbate non-computation overhead
Monolithic Optimization Space
- Main Challenges of Enabling A Monolithic Kernel Optimization Space
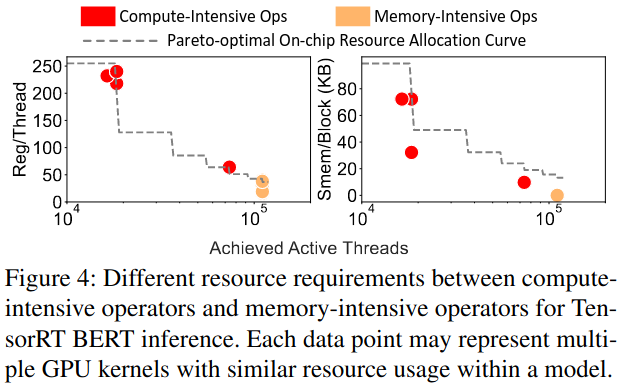
Challenge 1: Resource incompatibility between compute-intensive and memory-intensive operators
Challenge 2: Extremely high implementation cost and huge tuning space
System Design
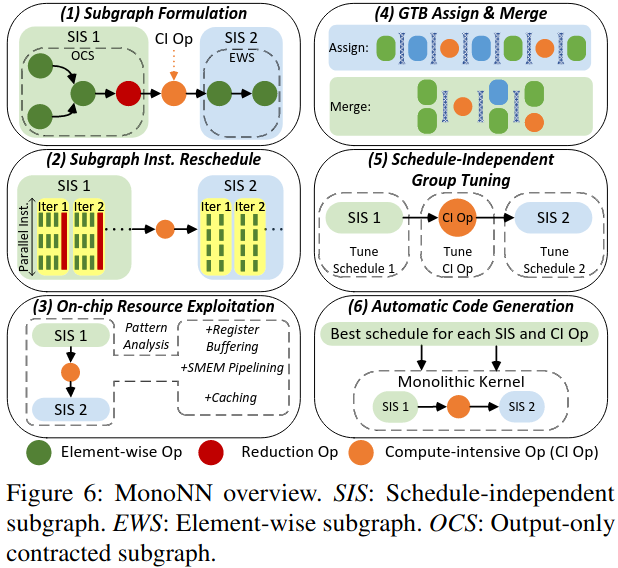
Exploiting Hidden Parallelism for Memory-intensive Subgraphs
Memory-intensive Subgraph Formulation
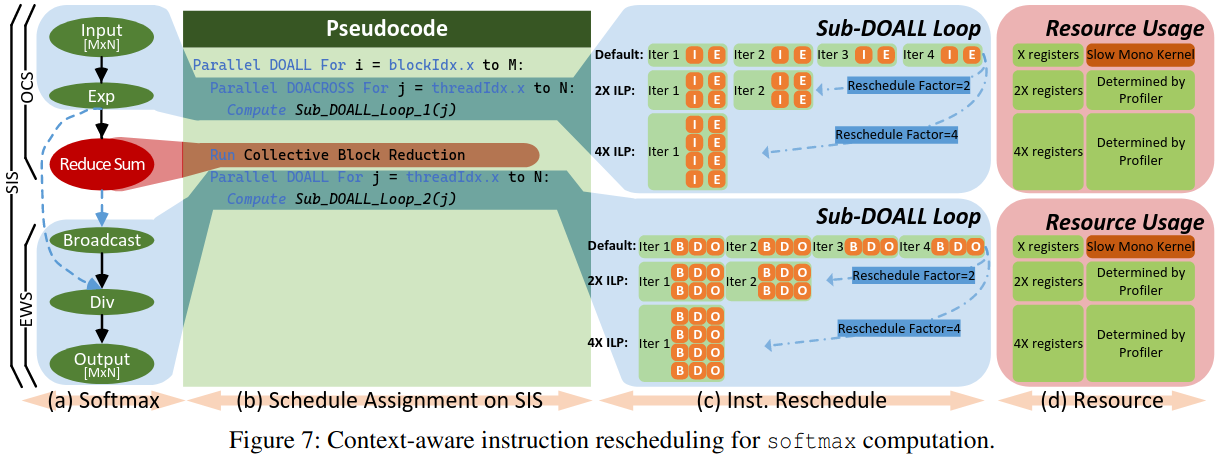
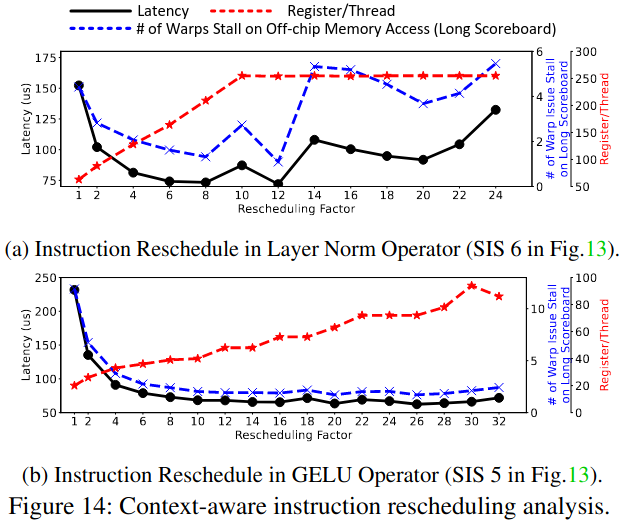
Context-Aware Instruction Rescheduling
DOALL循环: 循环的每次迭代之间完全没有数据依赖关系
for(i = 0; i < n; i++)
C[i] = A[i] + B[i] // 每次迭代都是独立的
DOACROSS循环: 循环的迭代之间存在数据依赖关系
for(i = 1; i < n; i++)
A[i] = A[i - 1] + B[i] // 当前迭代依赖前一次迭代的结果
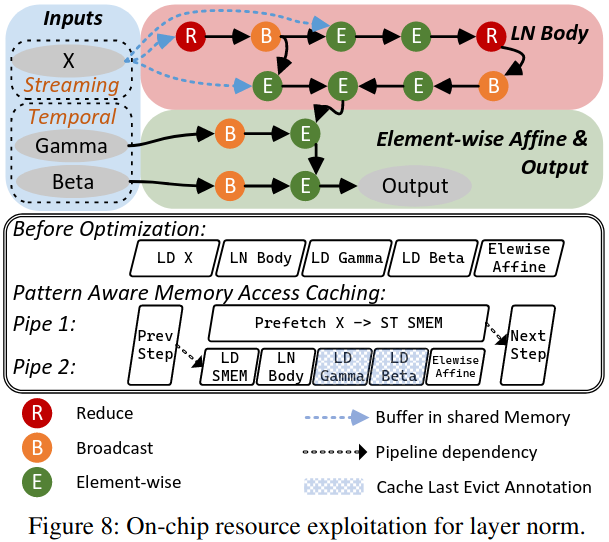
On-Chip Resource Exploitation
- Streaming Access Optimization:输入的张量的每个元素只被访问一次,利用共享内存进行流水线访问
- Temporal Access Optimization:输入张量的元素被多次访问,使用缓存提示来延长数据在缓存中的保留时间
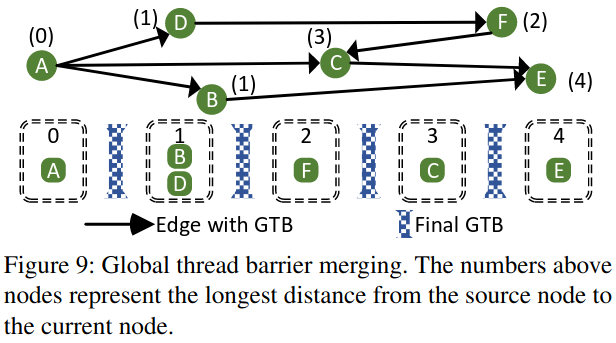
Global Thread Barrier Merging
The MonoNN Compiler
Optimization Space Abstraction
Code generation schedule of each operator in a neural network
Context-aware instruction rescheduling factor
TLP and on-chip resource of the overall monolithic kernel
Evaluation
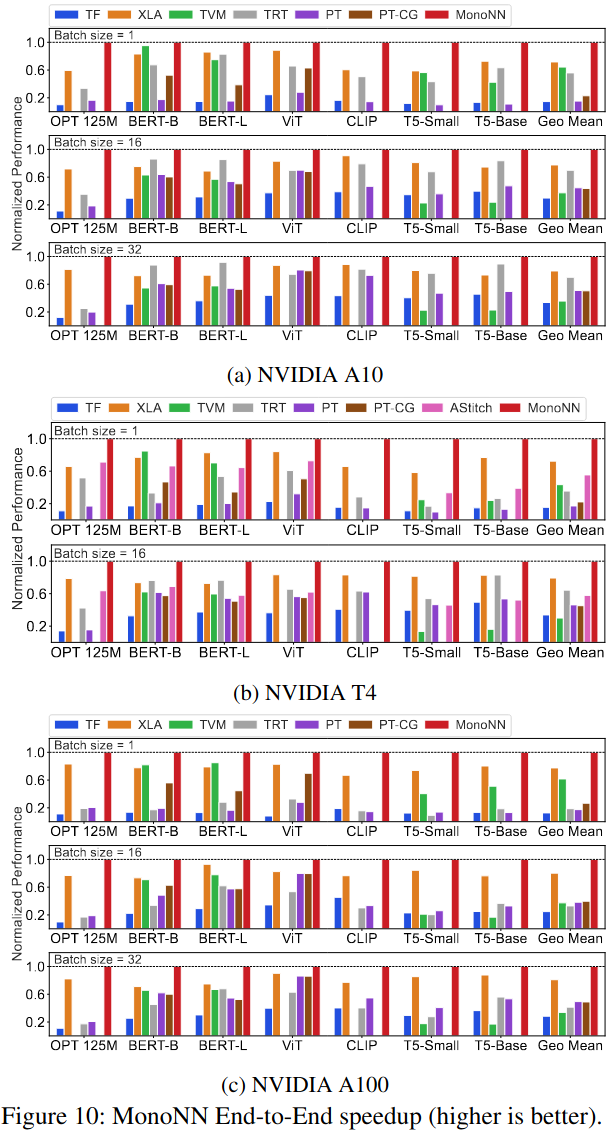
End-to-End Performance Comparison
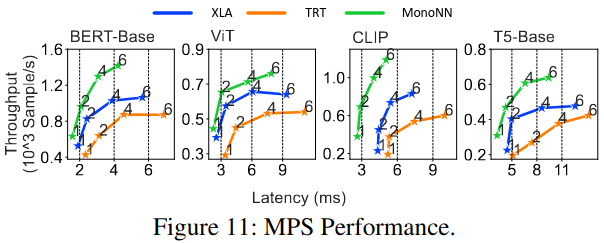
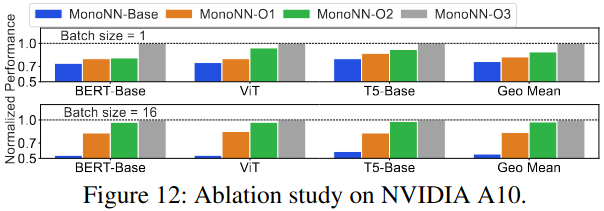
MonoNN Optimization Breakdown
Reference
FEATURED TAGS
Genetic Algorithm
Multi-objective Optimization
Instruction-Level Parallelism(ILP)
Compiler
Deep Learning Accelerators
Tensor Compiler
Compiler Optimization
Code Generation
Heterogeneous Systems
Operator Fusion
Deep Neural Network
Recursive Tensor Execution
Deep Learning
Classical Machine Learning
Compiler Optimizations
Bayesian Optimization
Autotuning
Spatial Accelerators
Tensor Computations
Code Reproduction
Neural Processing Units
Polyhedral Model
Auto-tuning
Machine Learning Compiler
Neural Network
Program Transformations
Tensor Programs
Deep learning
Tensor Program Optimizer
Search Algorithm
Compiler Infrastructure
Scalalbe and Modular Compiler Systems
Tensor Computation
GPU Task Scheduling
GPU Streams
Tensor Expression Language
Automated Program optimization Framework
AI compiler
memory hierarchy
data locality
tiling fusion
polyhedral model
scheduling
domain-specific architectures
memory intensive
TVM
Sparse Tensor Algebra
Sparse Iteration Spaces
Optimizing Transformations
Tensor Operations
Machine Learning
Model Scoring
AI Compiler
Memory-Intensive Computation
Fusion
Neural Networks
Dataflow
Domain specific Language
Programmable Domain-specific Acclerators
Mapping Space Search
Gradient-based Search
Deep Learning Systems
Systems for Machine Learning
Programming Models
Compilation
Design Space Exploration
Tile Size Optimization
Performance Modeling
High-Performance Tensor Program
Tensor Language Model
Tensor Expression
GPU
Loop Transformations
Vectorization and Parallelization
Hierarchical Classifier
TVM API
Optimizing Compilers
Halide
Pytorch
Optimizing Tensor Programs
Gradient Descent
debug
Automatic Tensor Program Tuning
Operators Fusion
Tensor Program
Cost Model
Weekly Schedule
Spatio-temporal Schedule
tensor compilers
auto-tuning
tensor program optimization
compute schedules
Tensor Compilers
Data Processing Pipeline
Mobile Devices
Layout Transformations
Transformer
Design space exploration
GPU kernel optimization
Compilers
Group Tuning Technique
Tensor Processing Unit
Hardware-software Codeisgn
Data Analysis
Adaptive Systems
Program Auto-tuning
python api
Code Optimization
Distributed Systems
High Performance Computing
code generation
compiler optimization
tensor computation
Instructions Integration
Code rewriting
Tensor Computing
DSL
CodeReproduction
Deep Learning Compiler
Loop Program Analysis
Nested Data Parallelism
Loop Fusion
C++
Machine Learning System
Decision Forest
Optimizfing Compiler
Decision Tree Ensemble
Decision Tree Inference
Parallelization
Optimizing Compiler
decision trees
random forest
machine learning
parallel processing
multithreading
Tree Structure
Performance Model
Code generation
Compiler optimization
Tensor computation
accelerator
neural networks
optimizing compilers
autotuning
performance models
deep neural networks
compilers
auto-scheduling
tensor programs
Tile size optimization
Performance modeling
Program Functionalization
affine transformations
loop optimization
Performance Optimization
Subgraph Similarity
deep learning compiler
Intra- and Inter-Operator Parallelisms
ILP
tile-size
operator fusion
cost model
graph partition
zero-shot tuning
tensor program
kernel orchestration
machine learning compiler
Loop tiling
Locality
Polyhedral compilation
Optimizing Transformation
Sparse Tensors
Asymptotic Analysis
Automatic Scheduling
Data Movement
Optimization
Operation Fusion
Compute-Intensive
Automatic Exploration
data reuse
deep reuse
Tensorize
docker
graph substitution
compiler
Just-in-time compiler
graph
Tensor program
construction tensor compilation
graph traversal
Markov analysis
Deep Learning Compilation
Tensor Program Auto-Tuning
Decision Tree
Search-based code generation
Domain specific lanuages
Parallel architectures
Dynamic neural network
mobile device
spatial accelerate
software mapping
reinforcement learning
Computation Graph
Graph Scheduling and Transformation
Graph-level Optimization
Operator-level Optimization
Partitioning Algorithms
IR Design
Parallel programming languages
Software performance
Digitial signal processing
Retargetable compilers
Equational logic and rewriting
Tensor-level Memory Management
Code Generation and Optimizations
Scheduling
Sparse Tensor
Auto-Scheduling
Tensor
Coarse-Grained Reconfigurable Architecture
Graph Neural Network
Reinforcement Learning
Auto-Tuning
Domain-Specific Accelerator
Deep learning compiler
Long context
Memory optimization
code analysis
transformer
architecture-mapping
DRAM-PIM
LLM