Contributions
- a tensor-expression-based global analysis to identify critical partitioning points
- a semantic preserving transformations approach that use affine transformation to simplify the tensor expressions of each subprogram
Motivation
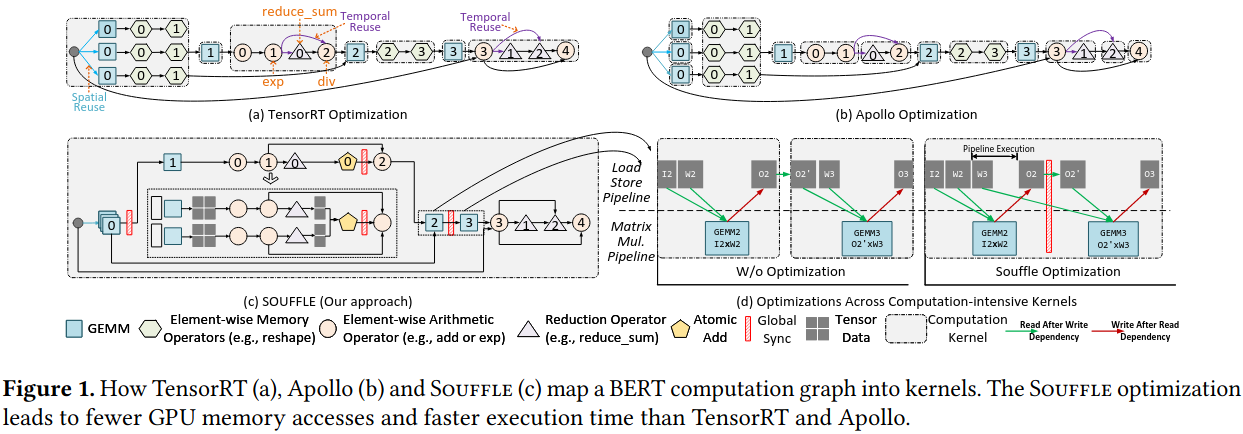
Fail to explore optimization between memory- and compute-intensive kernels: manually crafted rules cannot cover a diverse set of computation patterns and miss the optimization opportunity in this case
Suboptimal fusion strategy for reduction operators
Poor optimiztions across computation-intensive kernels
post-souffle-example.png
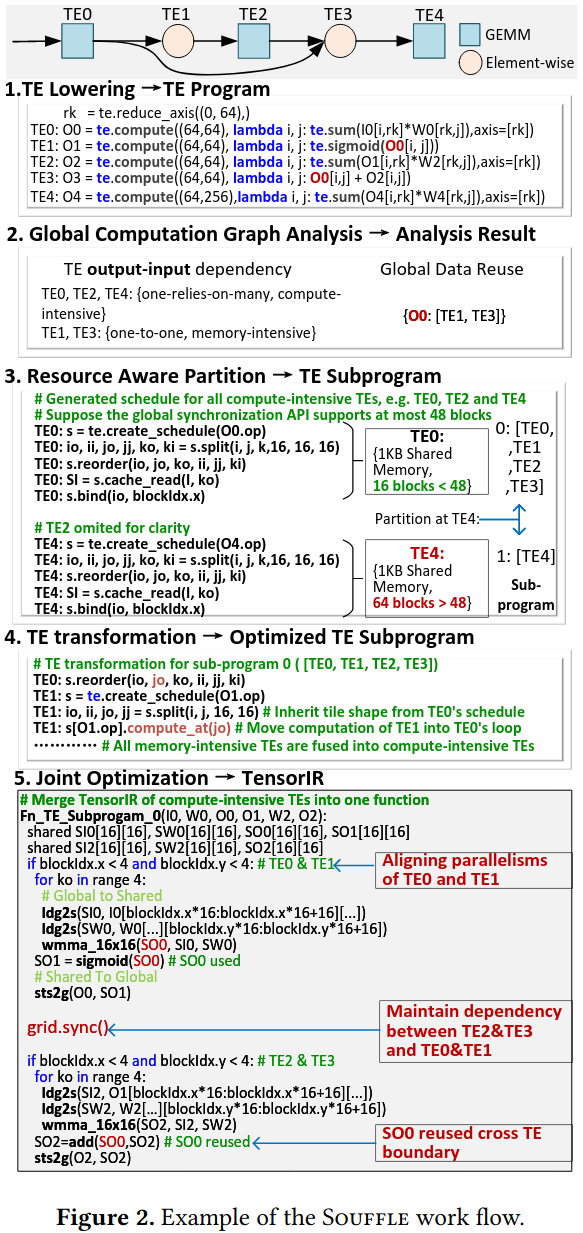
Global Computation Graph Analysis
- identifying data reuse opportunities
- intra-TE element-wise dependency analysis
- TE characterization
- TE Program Partitioning
Semantic-preserving TE Transfromations
- Horizontal transformation for independent TEs

- Vertical transformation for one-relies-on-one TEs

-
Schedule TEs
-
Merging TEs Schedule
-
Optimizations within a Subprogram: Instruction-level optimization、Tensor reuse optimization
-
Put it all together

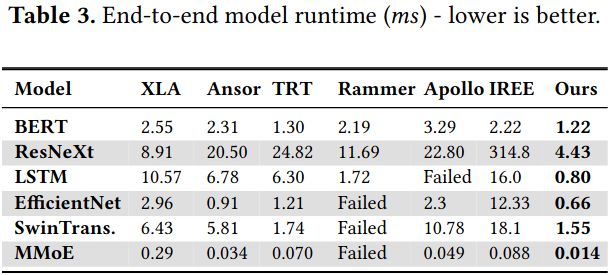
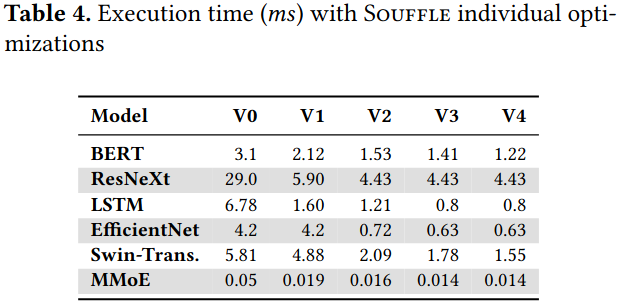
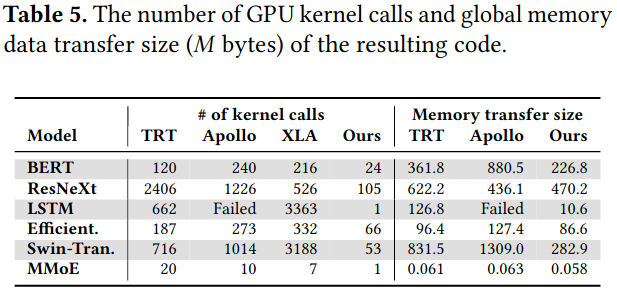
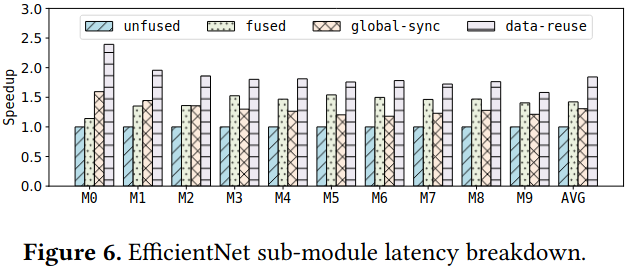
Evaluation
FEATURED TAGS
Genetic Algorithm
Multi-objective Optimization
Instruction-Level Parallelism(ILP)
Compiler
Deep Learning Accelerators
Tensor Compiler
Compiler Optimization
Code Generation
Heterogeneous Systems
Operator Fusion
Deep Neural Network
Recursive Tensor Execution
Deep Learning
Classical Machine Learning
Compiler Optimizations
Bayesian Optimization
Autotuning
Spatial Accelerators
Tensor Computations
Code Reproduction
Neural Processing Units
Polyhedral Model
Auto-tuning
Machine Learning Compiler
Neural Network
Program Transformations
Tensor Programs
Deep learning
Tensor Program Optimizer
Search Algorithm
Compiler Infrastructure
Scalalbe and Modular Compiler Systems
Tensor Computation
GPU Task Scheduling
GPU Streams
Tensor Expression Language
Automated Program optimization Framework
AI compiler
memory hierarchy
data locality
tiling fusion
polyhedral model
scheduling
domain-specific architectures
memory intensive
TVM
Sparse Tensor Algebra
Sparse Iteration Spaces
Optimizing Transformations
Tensor Operations
Machine Learning
Model Scoring
AI Compiler
Memory-Intensive Computation
Fusion
Neural Networks
Dataflow
Domain specific Language
Programmable Domain-specific Acclerators
Mapping Space Search
Gradient-based Search
Deep Learning Systems
Systems for Machine Learning
Programming Models
Compilation
Design Space Exploration
Tile Size Optimization
Performance Modeling
High-Performance Tensor Program
Tensor Language Model
Tensor Expression
GPU
Loop Transformations
Vectorization and Parallelization
Hierarchical Classifier
TVM API
Optimizing Compilers
Halide
Pytorch
Optimizing Tensor Programs
Gradient Descent
debug
Automatic Tensor Program Tuning
Operators Fusion
Tensor Program
Cost Model
Weekly Schedule
Spatio-temporal Schedule
tensor compilers
auto-tuning
tensor program optimization
compute schedules
Tensor Compilers
Data Processing Pipeline
Mobile Devices
Layout Transformations
Transformer
Design space exploration
GPU kernel optimization
Compilers
Group Tuning Technique
Tensor Processing Unit
Hardware-software Codeisgn
Data Analysis
Adaptive Systems
Program Auto-tuning
python api
Code Optimization
Distributed Systems
High Performance Computing
code generation
compiler optimization
tensor computation
Instructions Integration
Code rewriting
Tensor Computing
DSL
CodeReproduction
Deep Learning Compiler
Loop Program Analysis
Nested Data Parallelism
Loop Fusion
C++
Machine Learning System
Decision Forest
Optimizfing Compiler
Decision Tree Ensemble
Decision Tree Inference
Parallelization
Optimizing Compiler
decision trees
random forest
machine learning
parallel processing
multithreading
Tree Structure
Performance Model
Code generation
Compiler optimization
Tensor computation
accelerator
neural networks
optimizing compilers
autotuning
performance models
deep neural networks
compilers
auto-scheduling
tensor programs
Tile size optimization
Performance modeling
Program Functionalization
affine transformations
loop optimization
Performance Optimization
Subgraph Similarity
deep learning compiler
Intra- and Inter-Operator Parallelisms
ILP
tile-size
operator fusion
cost model
graph partition
zero-shot tuning
tensor program
kernel orchestration
machine learning compiler
Loop tiling
Locality
Polyhedral compilation
Optimizing Transformation
Sparse Tensors
Asymptotic Analysis
Automatic Scheduling
Data Movement
Optimization
Operation Fusion
Compute-Intensive
Automatic Exploration
data reuse
deep reuse
Tensorize
docker
graph substitution
compiler
Just-in-time compiler
graph
Tensor program
construction tensor compilation
graph traversal
Markov analysis
Deep Learning Compilation
Tensor Program Auto-Tuning
Decision Tree
Search-based code generation
Domain specific lanuages
Parallel architectures
Dynamic neural network
mobile device
spatial accelerate
software mapping
reinforcement learning
Computation Graph
Graph Scheduling and Transformation
Graph-level Optimization
Operator-level Optimization
Partitioning Algorithms
IR Design
Parallel programming languages
Software performance
Digitial signal processing
Retargetable compilers
Equational logic and rewriting
Tensor-level Memory Management
Code Generation and Optimizations
Scheduling
Sparse Tensor
Auto-Scheduling
Tensor
Coarse-Grained Reconfigurable Architecture
Graph Neural Network
Reinforcement Learning
Auto-Tuning
Domain-Specific Accelerator
Deep learning compiler
Long context
Memory optimization
code analysis
transformer
architecture-mapping
DRAM-PIM
LLM