Motivation
面临的挑战:
(1) complex two-level dependencies combined with just-in-time demand exacerbates training/inference inefficiency—hierarchical data reuse technique; 算子级一对多依赖导致producer被多次重复计算,降低了训练和推理效率,增加了CPU-GPU上下文切换和框架调度开销
(2) irregular tensor shapes in real-world production workloads often lead to poor parallelism control and servere performance issues in the current ML compilers—an adaptive thread mapping technique 现有编译器生成的线程映射方案要么块太小要么块太少,无法充分利用硬件
不规则张量形状导致GPU并行度不佳,硬件利用率低
- 小线程块问题 论文中的举例: <750000, 32> → <750000> 行规约操作 GPU硬件限制: 同时能执行的线程块数量有上限,实际需要750000线程块,结果大部分线程块需要等待,并行度严重不足 需要频繁切换线程块,上下文切换开销,线程块太小,无法充分利用GPU的计算单元
- 小线程块数量问题 论文中的举例: <64, 30000> → <64> 行规约操作 生成64个线程块,每个线程块大小为1024 GPU能同时调度160个线程块,实际只用了64个线程块 硬件未充分利用,GPU有能力并行处理更多任务,但任务数量不够,计算资源浪费,大量的流处理器(SM)处于空闲状态
Key Design Methodology
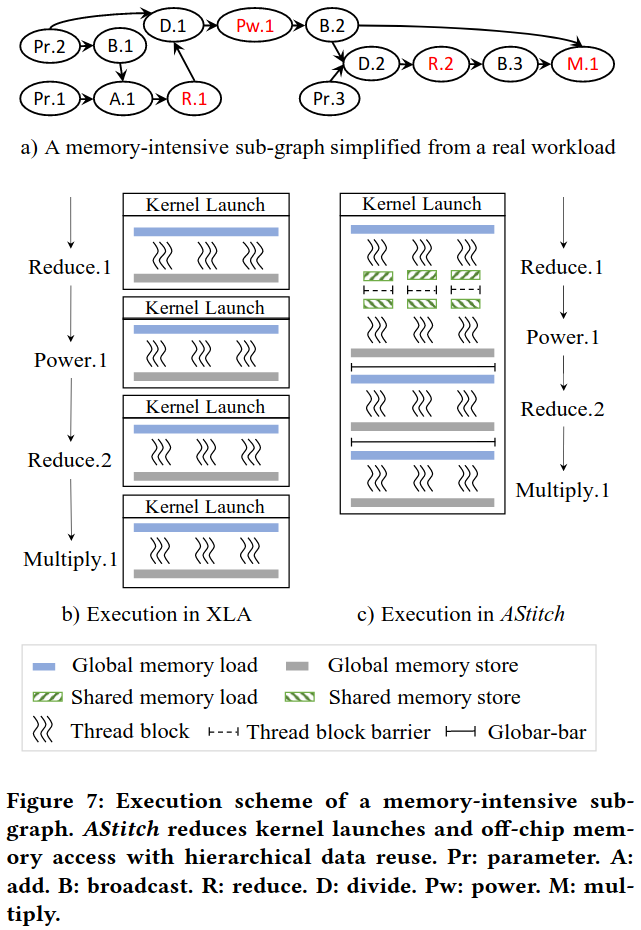
Operator-Stitching Scheme Abstraction:
Independent Scheme: 算子之间相互独立 Local Scheme: 相邻算子间是元素级一对一依赖,数据直接在寄存器中传递,无需额外内存访问 全局内存读取→寄存器计算→全局内存写入 每个线程独立工作,数据在寄存器中快速处理
Regional Scheme: 处理一对多元素级依赖关系,使用GPU共享内存,确保线程块级数据局部性,需要块内数据局部性,但避免全局内存访问 全局内存读取→共享内存存储→Block内同步→共享内存读取 Block内线程协作,通过共享内存实现数据重用
Global Scheme: 可以处理任意复杂的依赖关系,使用全局内存 全局内存读取→全局内存存储→全局同步→全局内存读取 所有线程协作,支持复杂依赖但需要全局同步
Hierarchical Data Reuse Illustration
Adaptive Thread Mapping:
- Task Packing: Horizontal packing(解决small block-size问题,将多个小块打包成一个大的线程块)、Vertical packing (减少块数量,满足global barrier要求,将多个线程块的任务打包到一个块中)
- Task Splitting: 解决small block count问题,将一个线程块内的任务拆分到多个块中,使用跨块院子操作实现行规约
Compiler Design and Optimizations
Stitching Scope Identification
- 子图识别: 使用BFS算法自动识别内存密集型子图,将每个子图替换为一个新的算子,称为stitch op
- remote stitching: 将没有数据依赖的stitch ops组合成更大的stitch op
Automatic Compiler Optimization Design
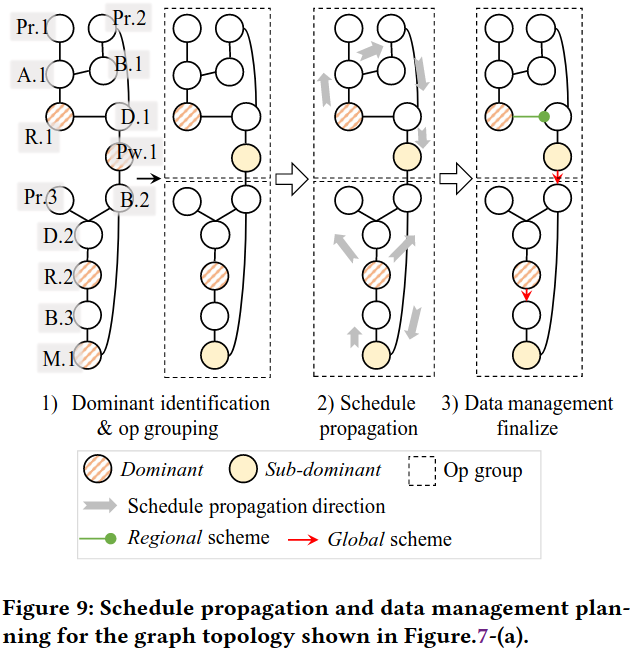
dominant identification and op grouping
- 候选主导操作识别 所有reduce操作的op、昂贵的元素级操作且后跟broadcast的op、输出操作的op
- 主导操作合并 如果两个候选主导操作之间只通过local scheme连接,选择一个作为最终主导,另一个作为次主导,优先选择reduce操作作为主导
- 操作分组 为每个主导操作形成一个组,添加所有通过local scheme连接的操作
adaptive thread mapping and schedule propagation
- 张量形状自适应 行数少但列数多 → 任务分割; 行数多 → 任务打包
- 调度传播 从主导操作向组内其他操作传播线程映射 数据局部性保证: 相同线程处理相关的数据元素,数据可以保持在寄存器中,避免重复的内存访问 同步开销最小化: 兼容的线程映射,操作间数据传递无需重组,减少同步和数据移动开销
Finalization
- 被动块局部性检查,检查生产者和消费者之间是否存在”块级数据局部性”,即同一个线程块内的线程所需要的数据,是否都由同一个线程块产生,若匹配可以使用共享内存,否则使用全局内存
- 主动块局部性适配,对于只包含元素级操作的组,主动调整其线程映射,使其与生产者组的输出模式匹配,从而实现块局部性
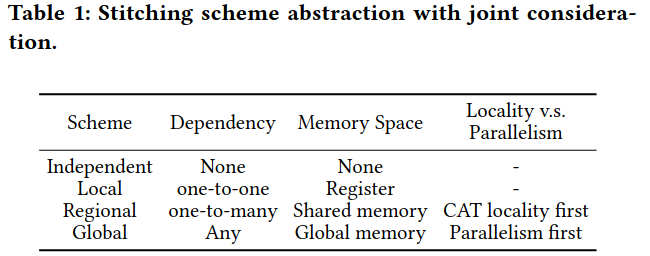
四种缝合方案 |方案类性|依赖关系|内存空间|局部性vs并行度| |:—:|:—:|:—:|:—:| |Independent|无|无|-| |Local|一对一|寄存器|-| |Regional|一对多|共享内存|优先局部性| |Global|任意|全局内存|优先并行度|
核心问题 内存密集型操作称为新的性能瓶颈 现有编译器的融合困境
- 进行融合,产生大量冗余计算,无法处理一对多的元素级依赖,浪费GPU资源
- 跳过融合,产生大量小内核,频繁的内核启动开销,大量的CPU、GPU上下文切换 不规则张量形状导致的并行度问题 张量形状不规整,现有编译器无法自适应,导致GPU利用率低下
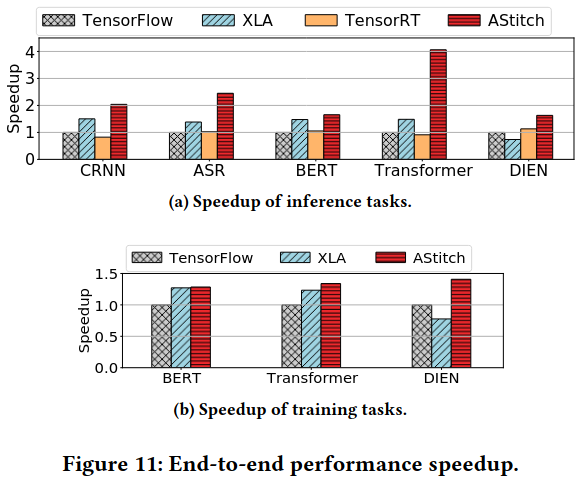
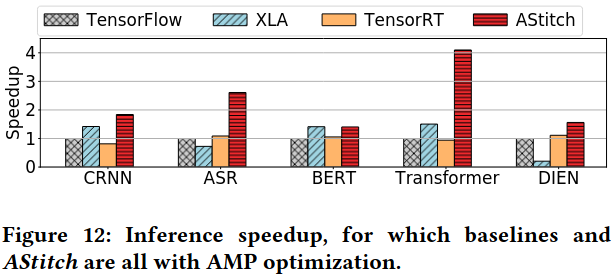
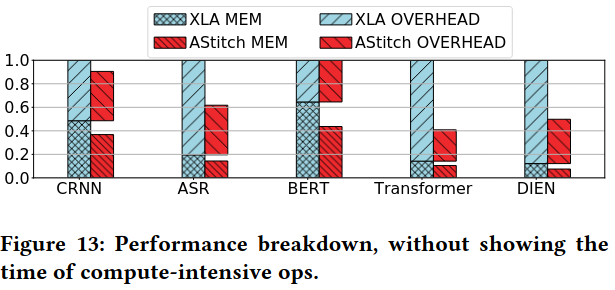
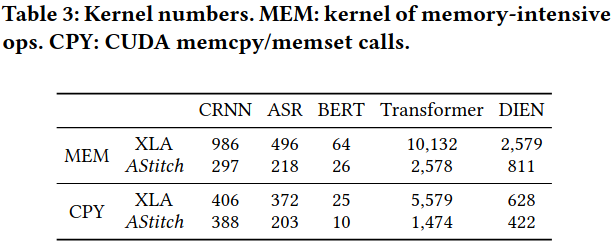
Evaluation