Motivation
传统机器学习模型缺乏共享的逻辑抽象,需要支持N各来自各种ML框架的操作符,M个部署环境,结果导致O(N*M)的组合爆炸问题,作者提出将N个操作符首先编译转换为K个核心张量操作,然后只需要确保K个核心操作在M个环境上高效运行,将复杂度从O(N*M)降低到O(N)+O(K*M),证明将传统机器学习运算统一到张量计算的可行性
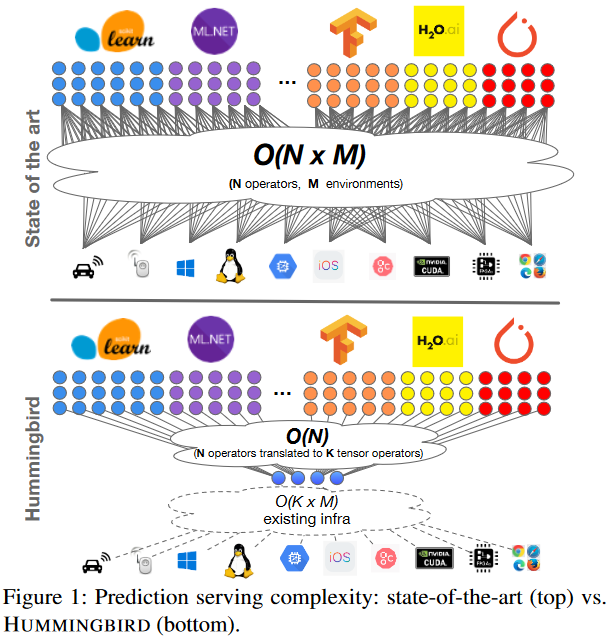
面临的挑战:
(1) 如何将传统预测流水线映射到张量计算:algebraic operators、algorithm operators(难点涉及任意数据访问和控制流决策)
(2) 如何实现张量编译后的传统ML操作符的高效执行
algebraic operators的特点:基于线性代数运算,运算是规则的、批量的、可并行的,可以用张量表示和计算
algorithm operators的特点:包含任意的数据访问模式,有复杂的控制流决策
algorithm转换张量计算的挑战:1. 需要将条件判断转换张量计算 2. 需要动态路径选择 3. 需要确保计算的正确性 4. 引入冗余计算
System Overview
System Architecture and Implementation
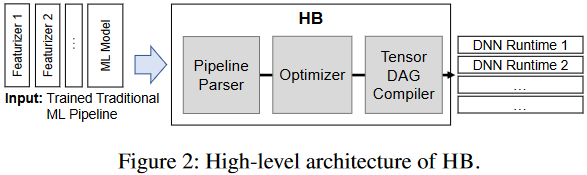
Compilation
Compiling Tree-based Models
Strategy 1: GEMM
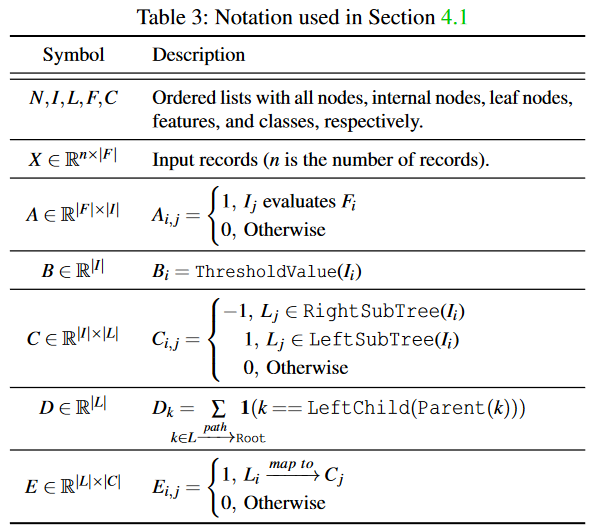
- A captures the relationship between input features and internal nodes
- B is set to the threshold value of each internal node
- C captures whether the internal node is a parent of that internal node, and if so, whether is in the left or right sub-tree
- D captures the count of the internal nodes in the from a leaf node to the tree root
- E captures the mapping between leaf nodes and the class labels

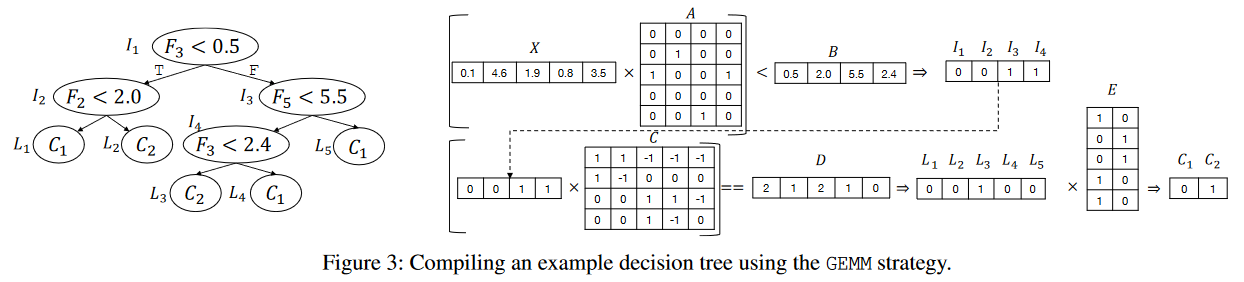
优点: 完全转换为矩阵运算,可以利用高度优化的GEMM实现,便于在GPU等硬件上并行执行 缺点:引入计算冗余,要评估所有节点,内存占用较大,需要存储完整的树结构信息 每个GEMM操作都需要处理所有节点,因此计算复杂度与节点总数成正比,即O(2^D)
Strategy 2: TreeTraversal (TT)

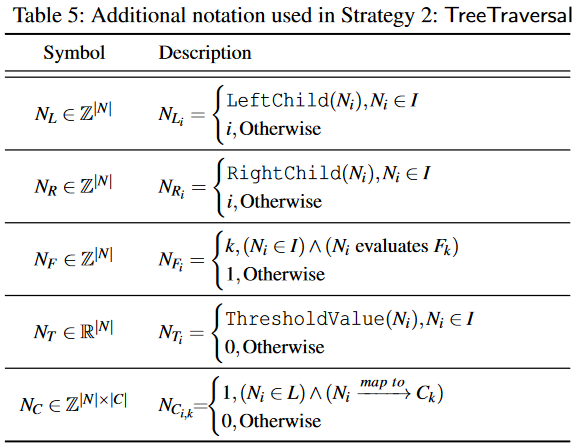
TT策略:只评估实际遍历路径上的节点,每个样本只计算必要的决策,通过索引直接访问下一个需要的节点,计算复杂度O(D)
Strategy 3: PerfectTreeTraversal (PTT)

| GEMM | TT | PTT | |
|---|---|---|---|
| 计算复杂度 | O(2^D) | O(D) | O(D) |
| 内存占用 | O(|F||N|+|N|^2+|C||N|) | O(|N|) | O(2^D) |
| 并行性能 | 高度并行 | 多次循环迭代 | 相比TT有更好的并行性 |
| 适用场景 | 浅树 | 深树 | 中等深度的树,完美二叉树效果最好 |
| 实现复杂度 | 相对简单 | 中等,需要处理节点遍历逻辑 | 相对复杂,需要处理树的转换和完美二叉树约束 |
| 扩展性 | 容易扩展到不同硬件 | 需考虑不同硬件的内容访问特性 | 受限于完美二叉树的要求,扩展性差 |
Summary of Other Techniques
Exploiting Automatic Broadcasting:当张量形状不同时,尺寸为1的维度会被自动扩展而不分配额外内存,但是会执行冗余比较,检查所有记录的特征值与所有词表值 Minimize Operator Invocations:在相同计算量的情况下,调用更少的运算符通常性能更好 Avoid Generating Large Intermediate Results Fixed Length Restriction on String Features
Optimizations
(1) Heuristics-based Strategy Selection (2) Runtime-independent Optimizations: Feature Selection Push-Down、Feature Selection Injection
Evaluation
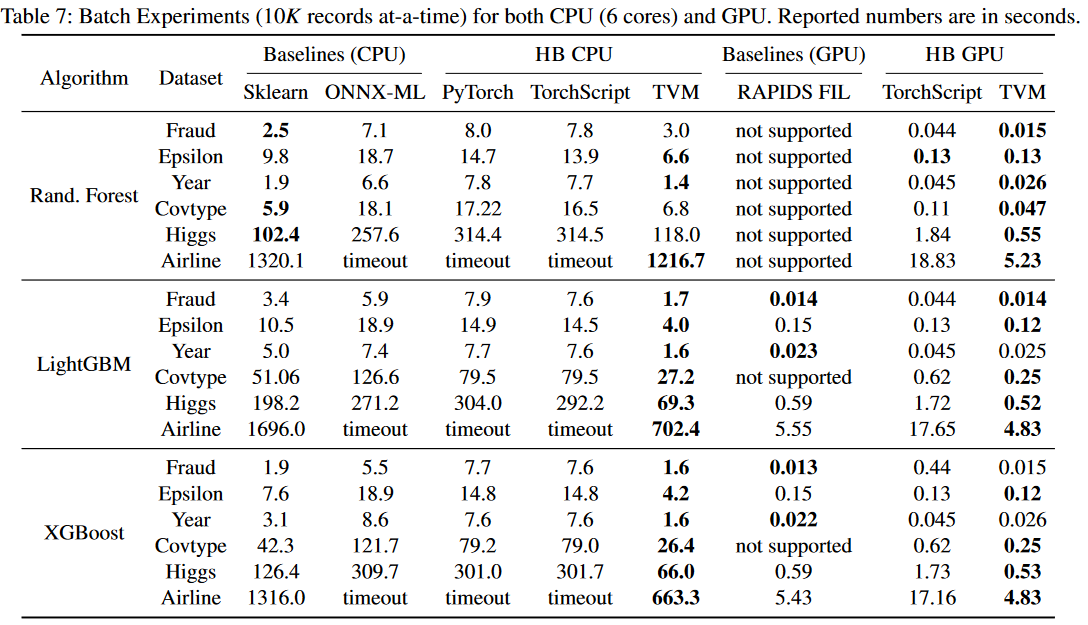
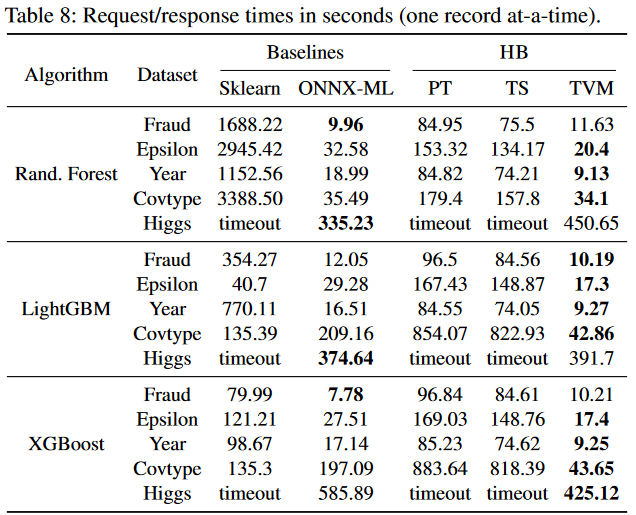
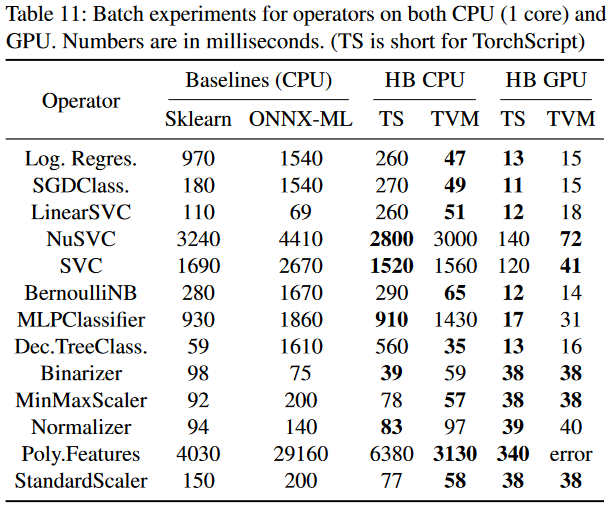
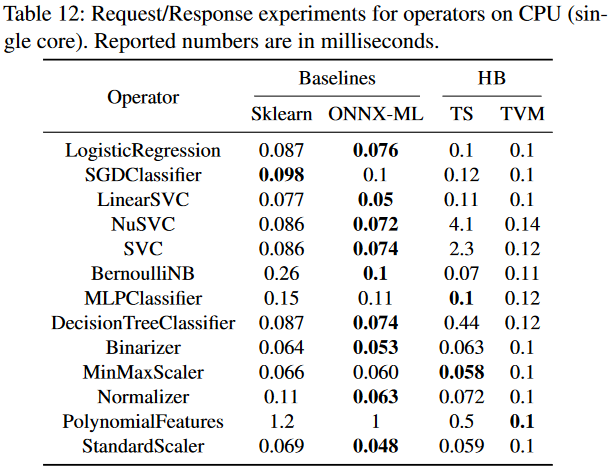
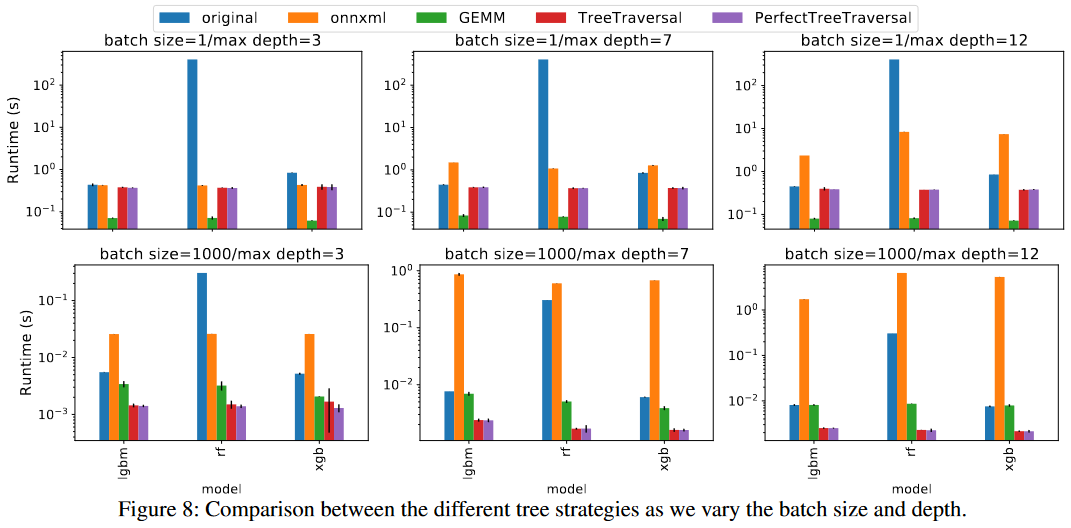
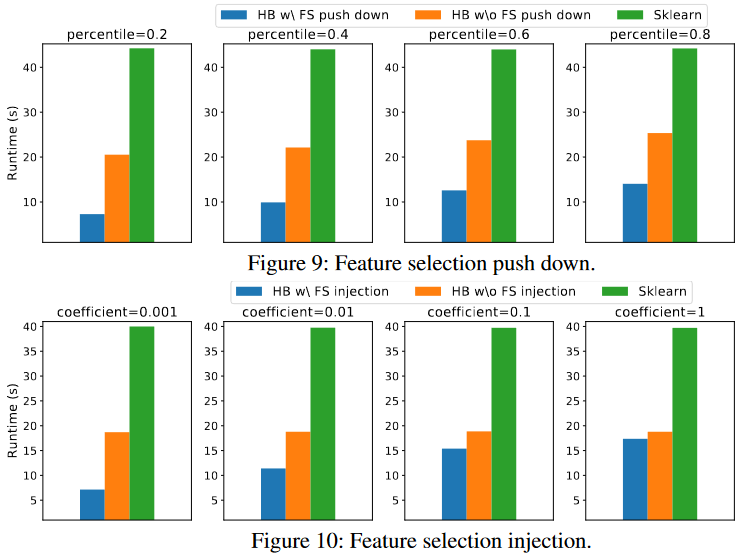
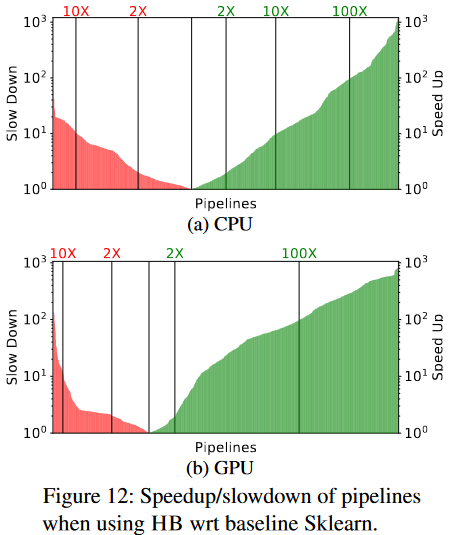
Thinking
(1) 技术局限性
- 不支持稀疏数据计算,作者也提到当前DNN框架对稀疏计算的支持比较原始
- 无法和好地支持文本特征提取,特别是基于正则表达式的分词器难以转换为张量计算
- 目前仅限于单GPU内存执行,缺乏分布式处理能力
(2) 实验方面的不足
- 实验主要集中在树模型和基本操作符上,对其他类型的传统ML模型覆盖不够全面
- 没有评估在资源受限环境下的性能表现
- 缺乏对模型编译时间的详细分析和优化讨论
(3) 优化策略的局限
- 当前的启发式测率选择规则是硬编码的,缺乏自适应机制
- 特征选择优化主要针对静态场景,对动态特征选择支持有限
- 没有充分考虑内存与计算的权衡优化
Reference
A Tensor Compiler for Unified Machine Learning Prediction Serving