Current solution
consider transfromations representable by a fixed set of predefined tensor operators
POR transformations:深度学习框架中已经内置的标准操作,如卷积、矩阵乘法、加法、激活函数—用积木搭建
General tensor algebra transformations:把操作拆解到更基础的数学表达式层面,可以生成全新的操作符—把积木拆开重新设计,创造处新的积木形状
The author’s proposal
exploer general tensor algebra transformations whose nodes are general tensor operators
面临的挑战:
(1) automatically discovering transformation opportunities between general expressions
(2) converting expressions back to kernels that be executed on DNN accelerators-expression instantiation
(3) quickly finding optimizing transformations in the search space of general tensor algebra transformations
Overview and Motivating Example
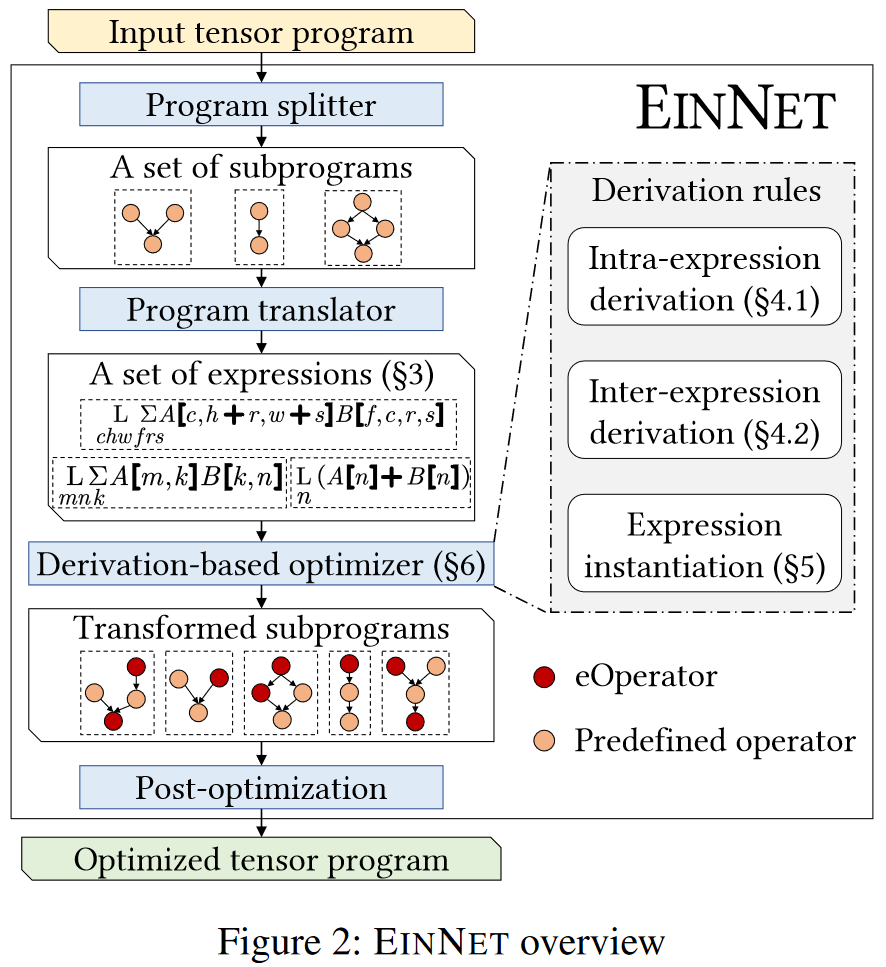
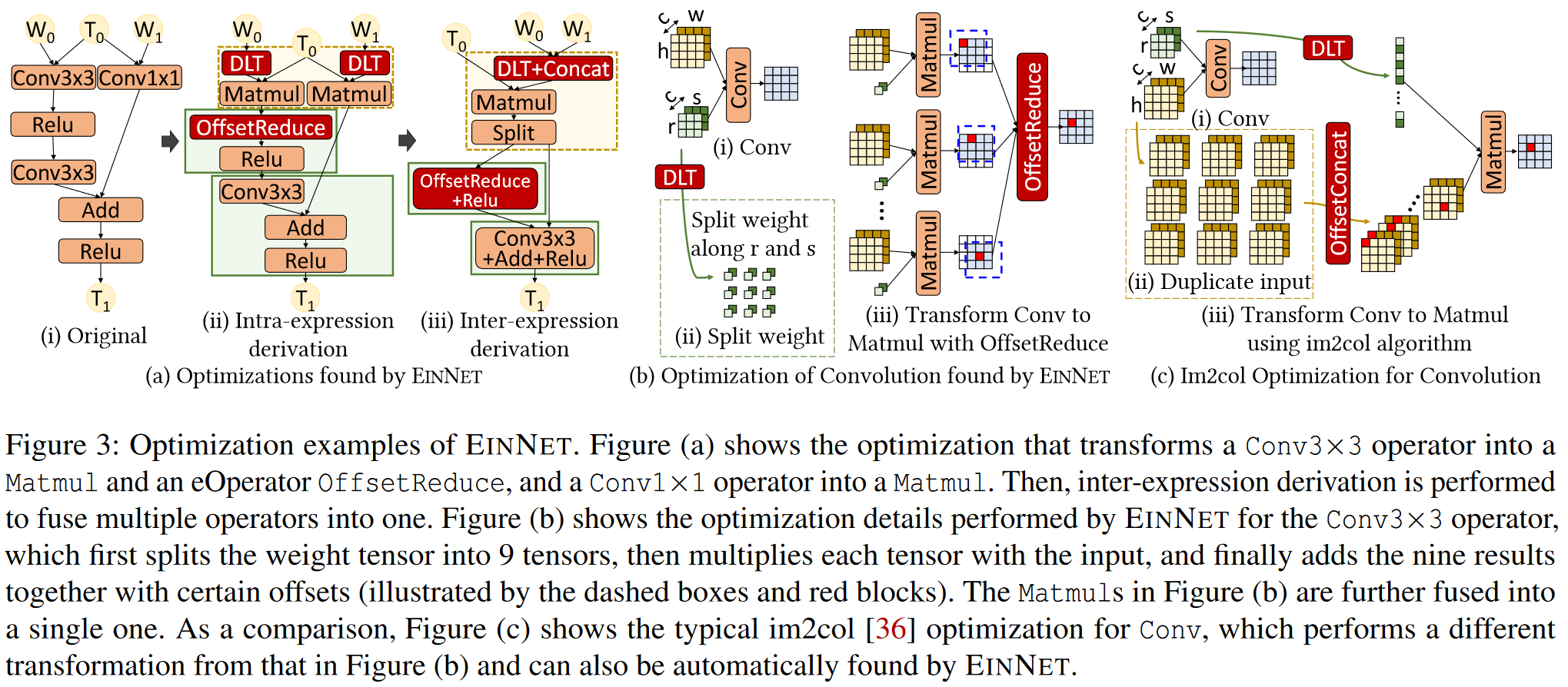
Derivation Rules
Intra-Expression Derivation
Summation splitting: 矩阵相乘AxBxC
A: [m x k]
B: [k x n]
C: [n x p]
未拆分
for i in range(m):
for j in range(p):
result[i, j] = 0
for k in range(K):
for n in range(N):
result[i, j] += A[i, k] * B[k, n] * C[n, j]
拆分后
temp = np.zeros((m, n))
for i in range(m):
for n in range(n):
for k in range(k):
temp[i, n] += A[i, k] * B[k, n]
result = np.zeros((m, p))
for i in range(m):
for j in range(p):
for n in range(n):
result[i, j] += temp[i, n] * C[n, j]
Variable substitution
# 输入:input[H, W, C]
# 卷积核:kernel[3, 3, C, F]
# 输出: output[H, W, F]
原始表达式
for h in range(H):
for w in range(W):
for f in range(F):
for r in range(3):
for s in range(3):
for c in range(C):
output[h, w, f] += input[h+r, w+s, c] * kernel[r, s, c, f]
替换后的表达式
for f in range(F):
# 遍历卷积核位置
for r in range(3):
for s range(3):
for t1 in range(r, H+r):
for t2 in range(s, W+s):
for c in range(C):
h = t1 - r
w = t2 - s
output[h, w, f] += input[t1, t2, c] * kernel[r, s, c, f]
Traversal merging 将矩阵A的每行先乘以一个系数v,然后与矩阵B相乘
未合并的表达式
for i in range(M):
for j in range(N):
temp = 0
for k in range(K):
scaled_a = {
for _ in range(1):
scaled_a = A[i, k] * v[i]
}
temp += scaled_a * B[k, j]
result[i, j] = temp
合并的表达式
for i in range(M):
for j in range(N):
temp = 0
for k in range(K):
temp += (A[i, k] * v[i]) * B[k, j]
result[i, j] = temp
Expression Instantiation
将一个表达式匹配到已有的操作符,直接使用优化好的库比自己生成新代码更高效
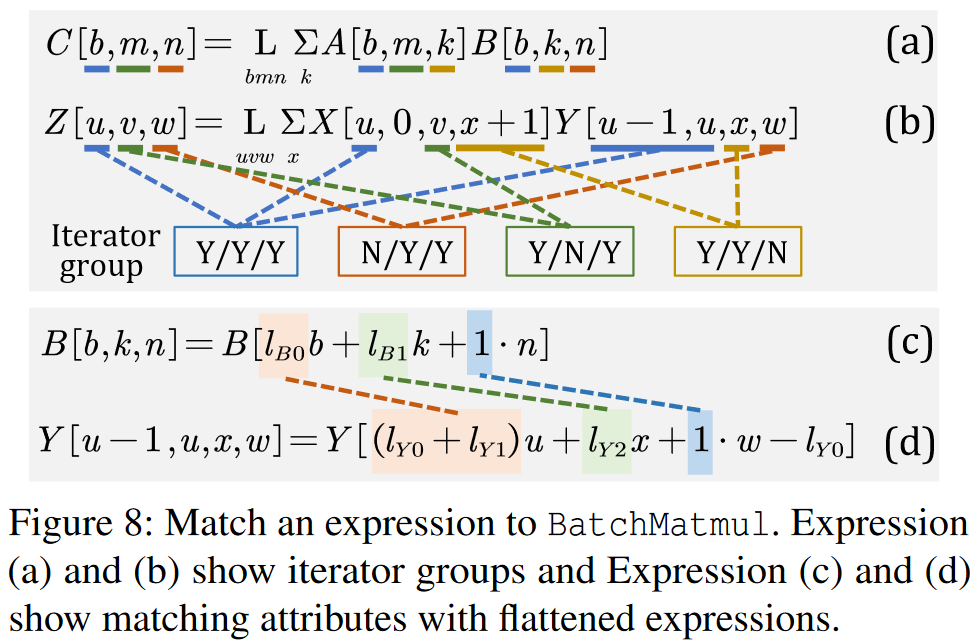
Operator Matching
- match tensors
- match iterators
- match operator attributes
eOperator Generation
处理无法匹配到预定义操作符的表达式,利用off-the-shelf kernel generation framework(eg. TVM)
Program Optimizer
基于距离的搜索算法
- Explorative derivation
- Converging derivation (快速向目标操作符收敛) Expression distance: 使用迭代器映射表匹配两个表达式中的迭代器、统计不匹配的迭代器总数作为距离

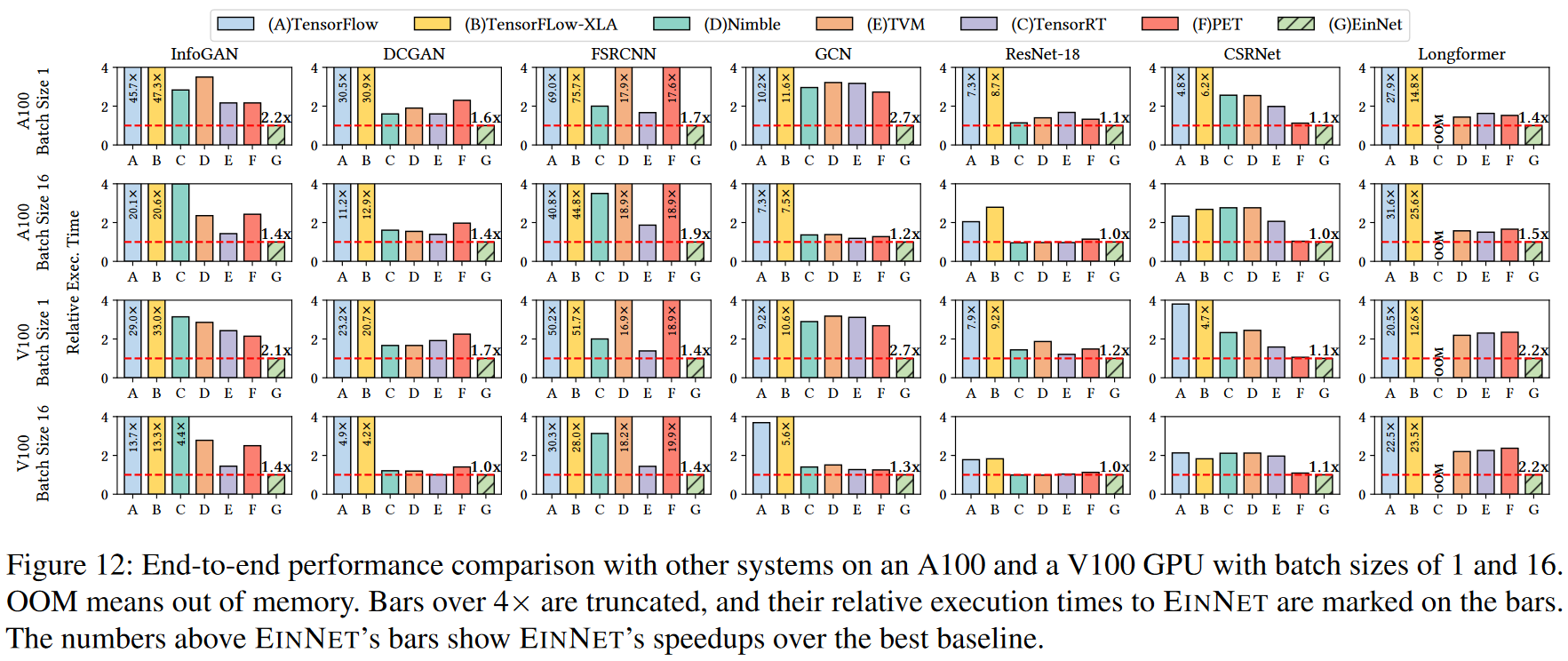
Evaluation
Thinking
(1) 只支持静态图,不支持动态图
静态图
# 批处理大小固定为32,输入维度固定为224*224
model = Model()
input = torch.randn(32, 3, 224, 224) #形状在编译时就确定
output = model(input)
动态图
# 批处理大小不固定,可能根据实际数据变化
model = Model()
batch_size = get_dynamic_batch_size()
input = torch.randn(batch_size, 3, 224, 224)
output = model(input)
(2) 本文主要关注计算优化,没有考虑内存带宽和缓存效应
(3) 相似的输入是否能得到相似的优化结果?
(4) 生成eOperator性能可能不如手工优化的版本(TVM)话说TVM生成效果不就是要比手工的好,但是在本文观点里面不一定比手工好
| PET | EINNET | |
|---|---|---|
| 核心思想 | 基于部分等价转换(partial equivalence) | 基于张量代数表达式的推导 |
| 优化空间 | 预定义算子空间内 | 可推导出新算子 |
| 转换方式 | 图级别的模式匹配和替换 | 数学表达式推导生成 |
| 验证机制 | 需额外的修正机制 | 数学推导规则保证 |
| 性能提升来源 | 来自已知优化模式的应用 | 全新的优化机会 |
Reference
EINNET: Optimizing Tensor Programs with Derivation-Based Transformations